For lack of rich competition, some of Nvidia’s top results in recent MLPerf were against itself, comparing its latest GPU, the H100 “Hopper”, to its current product, the A100.
nvidia
Although the chip giant Nvidia tends to cast a long shadow over the AI world, its ability to simply push competition out of the market may increase, if recent benchmark test results are any indication.
MLCommons, the industry association that oversees popular machine learning performance test, MLPerf, on Wednesday released the latest figures for “training” artificial neural networks. The preparation process showed the fewest competitors Nvidia had had in three years, and only one: CPU giant Intel.
In past tours, including Latest in JuneNvidia had two or more competitors it was up against, including Intel and Google with its “Tensor Processing Unit,” or TPU, and chip and chips from a British start-up. core graph; And in past rounds, the Chinese telecom giant Huawei.
also: Google and Nvidia split the highest scores in the MLPerf AI Training Benchmark
Due to the lack of competition, this time Nvidia swept all the top scores, while in June, the company shared the top spot with Google. Nvidia introduced systems using the A100 GPU that was discontinued several years ago, as well as the all-new H100 known as the “Hopper” GPU in honor of computing pioneer Grace Hopper. The H100 has the highest score on one of eight standardized tests, for the so-called recommendation systems that are commonly used to suggest products to people on the web.
Intel showed off two systems using its own Habana Gaudi2 chips, as well as systems named “Preview” which showed it would soon offer Xeon chips dubbed “Sapphire Rapids”.
Intel systems have proven to be much slower than Nvidia parts.
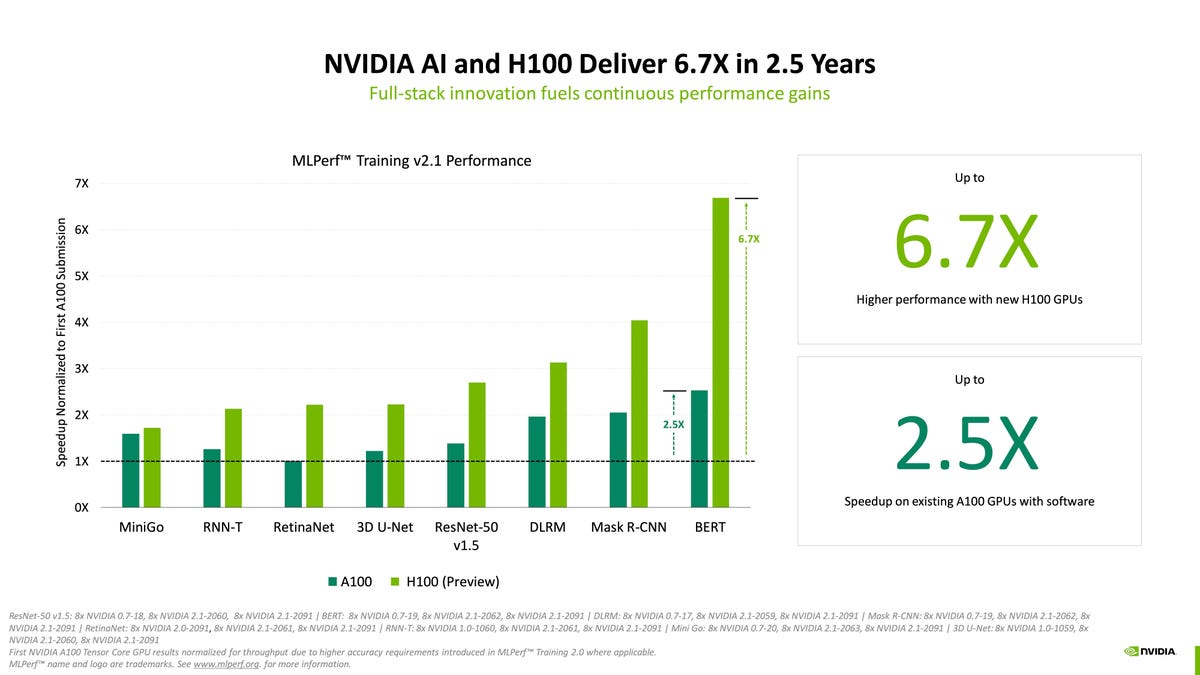
In a press release, Nvidia said, “H100 GPUs (also known as Hopper) scored training benchmarks across all eight MLPerf workloads. They delivered up to 6.7 times more performance than previous generation GPUs when they were first introduced in MLPerf training. By the same token, today’s A100 GPUs pack 2.5 times more power, thanks to advances in software.”
During an official press conference, Nvidia’s Dave Salvatore, Senior Product Manager for Artificial Intelligence and Cloud, focused on Hopper’s performance improvements and software tweaks on the A100. Salvatore showed both how Hopper accelerated performance for the A100 — a test of Nvidia against Nvidia, in other words — and also showed how Hopper managed to beat both the Intel Gaudi2 and Sapphire Rapids chips.
also: Graphcore brings new competition to Nvidia in the latest MLPerf AI standards
The lack of different sellers in and of itself does not indicate a trend since in previous rounds of MLPerf, individual sellers decided to skip the competition only to return in a later round.
Google did not respond to ZDNET’s request for comment on why it was not sharing this time.
In an email, Graphcore told ZDNET that it decided it currently had better places to dedicate its engineers’ time than the weeks or months it takes to prepare orders for MLPerf.
“The issue of diminishing returns has arisen,” Iain McKenzie, head of communications at Graphcore, told ZDNET via email, “meaning there will be an inevitable infinite leap, looping other seconds, and ever-larger system configurations.” . ”
McKenzie told ZDNET that Graphcore “may participate in future MLPerf rounds, but for now it doesn’t reflect areas of AI where we’re seeing more exciting progress.” MLPerf tasks are just “table stakes”.
Instead, he said, “we really want to focus our energies” on “opening up new possibilities for AI practitioners.” To that end, McKenzie said, “You can expect to see some exciting progress soon” from Graphcore, “for example in distribution models, as well as with GNNs,” or Graph Neural Networks.
In addition to Nvidia’s chips dominating the competition, all computer systems that scored the highest were those made by Nvidia and not those from the partners. This is also a change from the previous rounds of standardized testing. Usually, some vendors like Dell will score the highest for systems they bundle together using Nvidia chips. This time around, no systems vendor could beat Nvidia in Nvidia’s own use of its chips.
MLPerf training benchmark tests report the number of minutes it takes to adjust neural “weights” or parameters, until a computer program achieves the required minimum accuracy in a given task, a process referred to as “training” a neural network, where shorter time is better.
Although the highest scores often grab the headlines—and are emphasized to the press by vendors—in reality, MLPerf scores include a variety of systems and a wide range of scores, not just one single highest score.
In a phone conversation, MLCommons CEO David Kanter told ZDNET not to focus solely on the highest scores. The value of the set of criteria for companies evaluating the purchase of AI devices, Kanter said, is having a wide range of systems of different sizes with different types of performance.
The transmissions, numbering in the hundreds, range from machines with just a few regular processors on up to machines with thousands of AMD host processors and thousands of Nvidia GPUs, the kind of systems that score the highest.
“When it comes to machine learning training and heuristics, there are a variety of needs for all different levels of performance,” Kanter told ZDNET, “and part of the goal is to provide performance metrics that can be used across all of those different metrics..”
“There is just as much value in information about some of the smaller systems as there is in the larger ones,” Kanter said. “All of these systems are equally important and relevant but perhaps to different people.”
also: AI performance benchmark test, MLPerf, continues to gain followers
As for Graphcore and Google not participating this time around, Kanter said, “I’d like to see more requests,” adding, “I understand that for many companies, they may have to choose how engineering resources are invested.”
“I think you’ll see these things ebb and flow over time in different rounds” of the standard, Kanter said.
An interesting secondary effect of the lack of competition on Nvidia has meant that some of the higher scores for some training tasks now show not only an improvement over the previous time, but also a decline.
For example, in the venerable ImageNet task, where a neural network is trained to assign a label label to millions of images, the first result this time was the same as the third in June, an Nvidia-built system that took 19 seconds to train. This result came in June after the results of Google’s “TPU” chip, which came in at just 11.5 seconds and 14 seconds.
In response to a question about an earlier transmission, Nvidia told ZDNET in an email that its focus is on the H100 chip this time, not the A100. Nvidia also noted that progress has been made since the first A100 results in 2018. In that round of training benchmarks, Nvidia’s 8-way system took approximately 40 minutes to train the ResNet-50. In this week’s results, that time was shortened to less than thirty minutes.
Nvidia also talked about its speed advantage against Intel’s Gaudi2 AI chips and the upcoming Sapphire Rapids XEON processor.
nvidia
Asked about the death of competitive offerings and the viability of MLPerf, Nvidia’s Salvatore told reporters, “That’s a fair question,” adding, “We’re doing everything we can to encourage participation; industry standards thrive on participation.”
“Hopefully, as some new solutions continue to come to market from others, they will want to demonstrate the merits of these solutions and the quality of these solutions in an industry standard benchmark rather than making their own one-time performance claims, which are extremely difficult to verify,” Salvatore said.
A key component of MLPerf, Salvatore said, is the rigorous deployment of test preparation and code to keep test results clear and consistent across hundreds of applications from dozens of companies.
Besides benchmark results for MLPerf training, Wednesday’s edition of MLCommons also presented HPC test results, meaning, scientific computing, and supercomputers. Those orders included a mix of systems from Nvidia and partners, as well as the Fujitsu supercomputer Fugaku running its own chips.
A third competition, called TinyML, measures how well low-power, embedded chips perform when making inference, the part of machine learning where a trained neural network makes predictions.
This competition, in which Nvidia has not yet participated, has an interesting assortment of chips and offers from vendors such as Silicon Labs and Qualcomm, European tech giant STMicroelectronics, and startups OctoML, Syntiant and GreenWaves Technologies.
In one of the TinyML tests, an image recognition test using the CIFAR dataset and ResNet neural network, GreenWaves, which is headquartered in Grenoble, France, got the highest score for having the lowest data processing latency and coming up with a prediction. The company introduced the Gap9 AI accelerator in combination with the RISC processor.
In prepared notes, GreenWaves stated that Gap9 “provides very low power consumption over medium complexity neural networks such as the MobileNet chain in classification and detection tasks but also in complex and mixed precision recurrent neural networks such as ours.” LSTM based sound insulation. ”